# 策略副本
在使用指标公式时,我们发现同一个技术指标可以同时运行在多个品种之上,并且可以做到互不干扰。其实和我们生活中使用电脑登录多个QQ程序的原理相同,通俗的讲,技术指标被加载应用时,我们加载的并非是该技术指标的原版文件,而是该技术指标的副本(也可以理解使用的是复印件)。
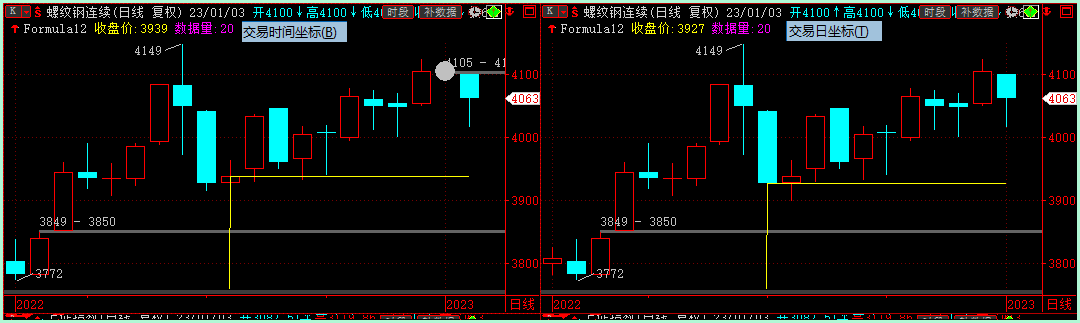
如下图所示,两个窗格中使用相同的技术指标Formula12公式,公式的内容如下所示,我们只输出指定位置的K线价格。我们会发现,在同品种、同周期、相同数据量的情况下,输出指定位置的收盘价不同。说明每个窗格下的策略公式都是独立执行的,两者之间并没有关联性,也能佐证上述副本机制的存在。这里产生差异的原因在哪?
起始很简单,我使用了不同的时间左边,使得两个k线图的起始位置不同,进而造成获得指定位置的结果出现了不同。
if barpos=10 then begin
bar10:close;
end
收盘价:bar10;
数据量:DATACOUNT;
2
3
4
5
副本的优点
- 可以避免重复创建大量的技术指标文件。
- 更有利于对策略进行源码的修改调整。
# 副本差异性分析
同一技术指标在应用时,造成不同副本之间的结果存在差异的原因有哪些?
生活中,假如我们培育出小麦品种麦田一号,在试种时,每块试验田的产量都不能完全相同,众所周知土壤成分、光照强度、降水、除草次数等等都可能是产量差异的因素。
技术指标也类似于与培育的种子,在对比时,由于干扰因素过多,所以采用控制变量法法进行分析。绝大部分用户认为,技术指标、品种、周期三者素完全相同时,结果应该也完全相同。针对这一想法,我们通过以下实验进行验证。
if barpos=10 then begin
bar10:close;
end
收盘价:bar10;
数据量:DATACOUNT;
2
3
4
5
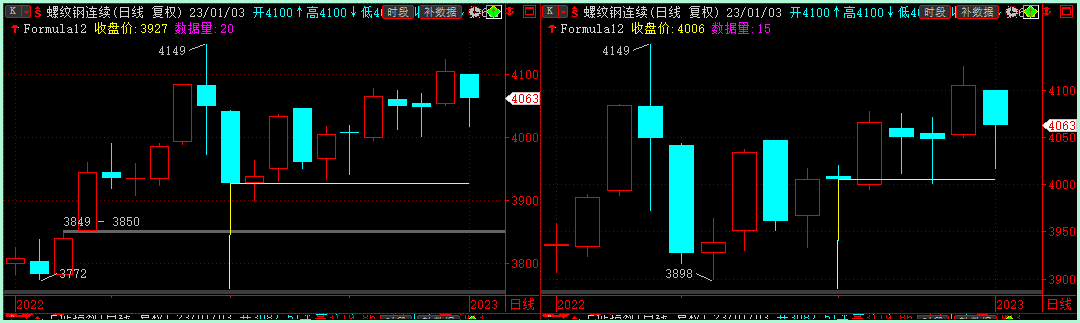
通过上述两个示例,可知影响计算结果的因素包括,使用的K线数据量、坐标类型(属于设置类)两个方面。其中数据量的差异影响会被的特定函数、执行逻辑等因素放大,造成更大的差异性。因此,当我们需要对比时,优先需要保证数据量一致。除此之外,以下情况也是影响因素。
- 不同计算个体之间独立进行,即使是同一技术指标,也会由于功能执行效率、执行时机等因素的影响,也会造成差异出现。比如:两台计算机之间或者不同功能之间。
- 从计算机底层分析,C多任务处理时,操作系统会采用时间片轮转的形式调度分配CPU资源,当计算所需时间大于行情间隔时间时,计算差异性也会出现。类似于两人排队买票时,取决于各队等候人数、买票速度。
计算产生的差异性也没有对错之分,就像世界上没有两片完全相同的树叶一样,产生差异的因素除上述数据量差异、设置差异、计算机底层因素等情况外,也不排除其他因素的影响,计算差异性实际碰到时需要结合具体使用环境进行分析。
首先,在数据量完全相同的前提下,指标在已经走完的K线上逐根计算时,等同于计算一段静态数据,无论如何运行其结果都是必然相同的。而最新K属于动态变化的数据,一般技术指标都能够达到在两笔间隔时间内完成计算,而且只要执行时机相同,其结果也会保持一致;或者虽然计算时机不同,但是由于各自获取到的行情价格恰好相同,其结果同样也会保持一致。 而产生所谓的不同、一般都是通过图表运算结果对比自定义数据、股票池、后台等功能产生的结果时,或者是不同软件之间进行对比,才会发现对差异性从而产生的疑惑。执行节点不同(时机点不同所使用的数据也不同)、算法结构不同等众多因素影的响下,采用这类对比方法,没有实际意义或者可以定义为错误的方法。
对于当前计算结果是否正确的判定,可以通过debugfile、debugout等调试函数,在代码执行时输出当时的计算因子项进行分析才是最行之有效的方法。