# 设置步骤
机器学习设置在菜单栏【分析】--【机器学习】中,本节将以线性回归算法为例,金字塔中的机器学习,目前提供的是监督学习中的分类和回归两种算法。逐步讲解金字塔中机器学习的设置过程。机器学习的主界面,如下图所示:
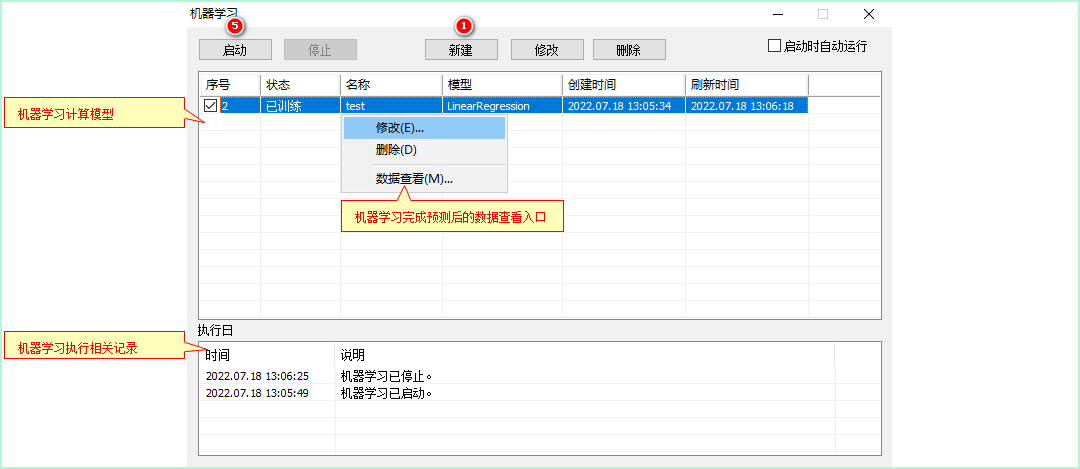
金字塔中的机器学习创建过程,通过主界面中的新建进入创建机器学习的设置界面。大致可以分为3步:
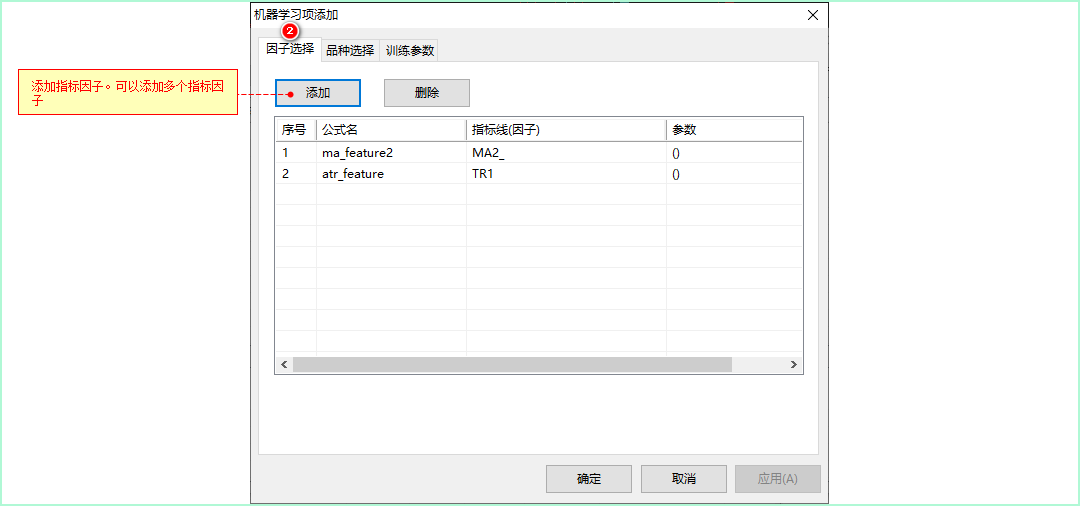
- 添加机器学习因子。
根据线性回归定义:,可知,是我们预测的目标,是我们指定的特征因子,是回归系数。因此,我们只需在下图中的因子选择中添加自己的因子组合即可。
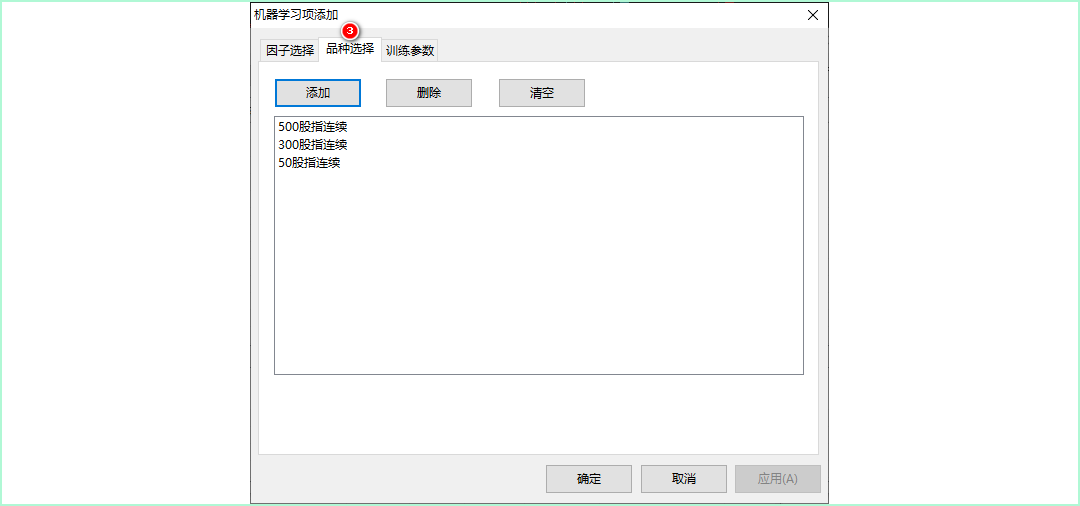
- 添加品种,用于机器学习进行样本训练使用。
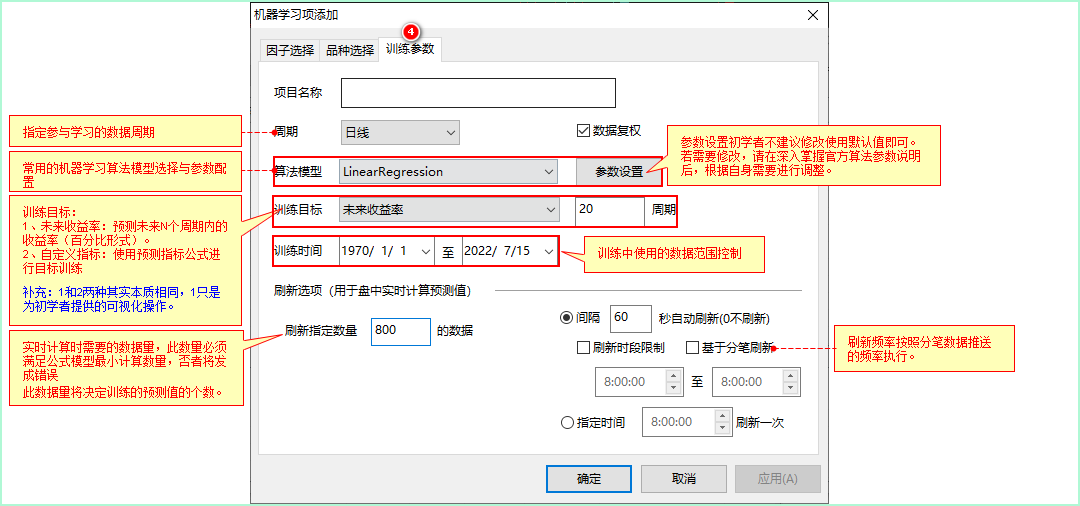
- 指定机器学习训练所使用的模型、样本数据、训练目标等信息。其中的
N周期的未来收益率,是为了便于用户直接使用而提供的。当然可以通过自定义指标公式作为训练目标。
说明
机器学习的过程没有对错之分,更没有标准答案,使用机器学习的目的是为了帮助我们找到分析研究中,不易发现的一些隐含或者复杂的数据特性规律;在分析研究中涉及到特征因子、周期、算法、参数设置相关组合关系,可能有无数个组合,因此盲目的尝试组合并不会为我们分析数据特性的效率带来提升。
机器学习支持盘中实时执行和调用,我们可以通过PREDICT函数获取预测结果。方法如下:
//test是机器学习的名称。
aa:PREDICT('test');
2
因此根据上图中的刷新指定数量的设置,我们可以得到小于等于800个预测值结果。
# 机器学习案例
# 回归算法案例
机器学习中,使用的算法模型、样本数据、特征因子等等,都会对最终学习的预测值有直接影响。例如我们采用LinearRegression模型和XGBRegressor模型,采用相同的因子指标等进行机器学习,其结果也有本质区别。
例如:我们使用收盘价的开平方作为特征因子,收盘价作为预测目标;
特征因子:就是我们常用的那些指标,大家可以参考范例进行拓展延伸 预测目标:这里注意真正做项目时候我们把需要预测的对象加了一个refx向后偏移,因为所谓预测就是拿当前数据预测未来
a:sqrt(c);
y:c;
创建2个机器学习条件test和test2,其中test采用LinearRegression模型,test2采用XGBRegressor模型。
test和test2设置中唯一的区别在于训练参数上,如下图所示:
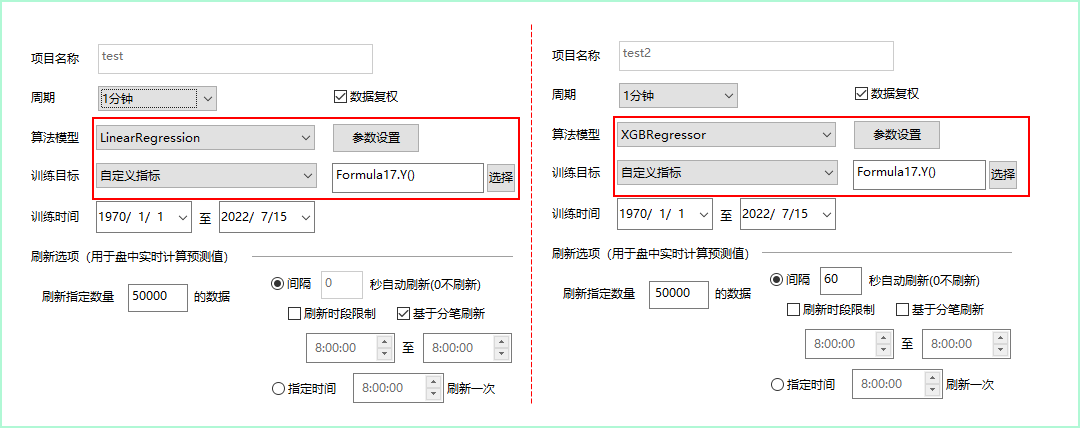
我们通过PEL指标获得预测值与收盘价的对比结果。
liner:PREDICT('test');
xgb_regress:PREDICT('test2');
y:c;
2
3
不同算法模型预测值与收盘价的效果如下:
总结
- 对于连续回归问题我们可以用上面案例绘制出,两条曲线通过观察了解预测结果的好坏;
- 从最后的效果图中我们可以看到,两者都很好的体现了价格的趋势走向,这主要源自我们选取的因子本身就是对预测目标有强关联性, 这个也是我们把机器学习运用在量化领域一个最重要的点要找到合适的因子。
- 可以看到xgbregress的模型效果比linear更好,这是因为线性回归的模型在上面已经提到了他的公式非常简单, 简单的线性乘法是无法非常好拟合开平这种非线性关系,而xgb这种集成算法效果往往会更好。
- 预测目标这里注意真正做项目时候我们把需要预测的对象加了一个refx向后偏移,因为所谓预测就是拿当前数据预测未来
- 综上:因子选择以及模型选择包括参数调优,这些都会影响我们最后的结果.
# 分类算法案例
设置方法不再赘述,请参考前面小结内容。分类算法的特征因子指标可以理解为判断条件;例如采用如下:
cond2:c>o;
//预测5日后是否收阳
y:refx(c>o,5);
2
//读取预测结果
a:PREDICT('test2');
//当前实际5日后的结果
y:refx(c>o,5);
//判断预测结果的准确性
bb:count(a=y,barpos)/barpos
2
3
4
5
6
7
8
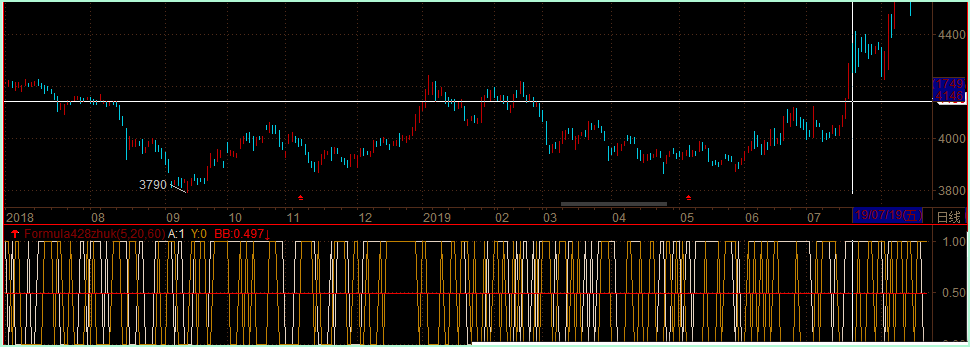
如下图所示,预测准确率为49.7%.
总结
- 对于分类问题,我们可以用准确率来判断,准确率可以用上面公式计算得到